当你有一台PC机假设是Windows系统,和一台android手机,你想让两者之间进行交流该怎么办呢?我们首先想到的肯定是通过wifi将二个设备连接到同一个局域网内,或者直接wifi-direct,但是可能的情况是环境里没有wifi,或者PC机压根就没有网卡等等情况,导致wifi连接并不可行。所以android手机和PC机默认连接方式是通过USB线缆将二者连接在一起,通过USB进行通讯。
然后,在手机中打开这个终端(terminal)应用,比如输入如下命令:
su
setprop service.adb.tcp.port 5555
stop adbd
start adbd
如果前面的配置正确无误,则可以得到:connected to 192.168.1.115:5555的输出。
这样,就可以使用adb来对手机进行调试了,此时也可以在Eclipse的设备列表中看到已经连接的手机设备了。
OK,说到这里既然物理的通讯链路已经解决了,那么站在软件的角度来说是个什么样子呢?
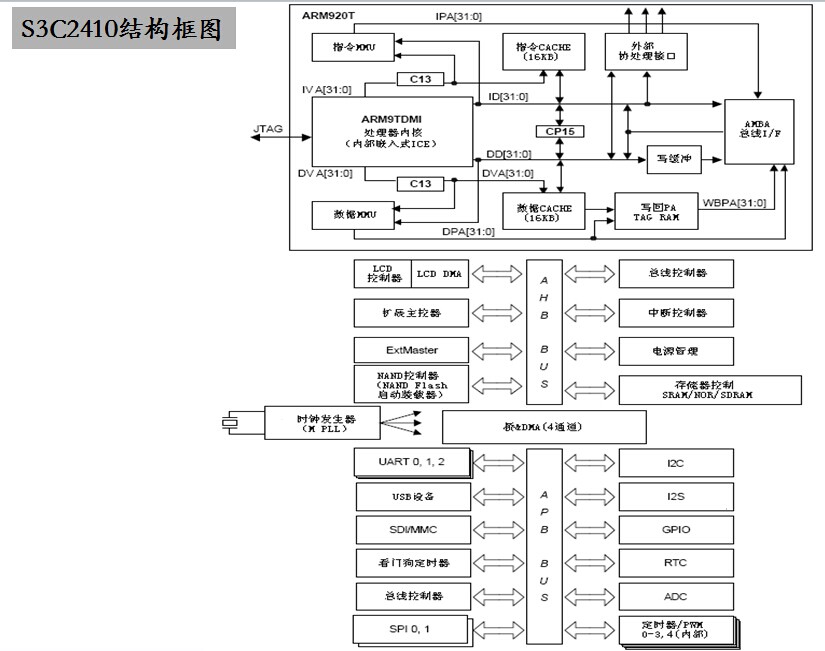
ADB由两个物理文件组成:
1. adb或adb.exe,运行于PC端,包括Linux、Windows、Mac OS等系统之中,通常是x86架构上。
2. adbd,运行于Android设备的底层Linux之中,ARMv5架构上。
从运行实体角度来看adb主要分为三部分:
1. adb client (在adb.exe中实现,运行在PC机上)
2. adb server (在adb.exe中实现,运行在PC机上)
3. adbd (在adbd中实现,是一个linux deamon程序,它实现了adb service的功能,运行在android手机上)
交互流程:
adb client <==> adb server <==> adbd
[PC端] [PC端] [android手机端]
下面为了行文方便,PC端统称为adb, 手机端称为adbd.
PC机上的adb(打开PC机的usb接口)与android上的adbd(打开手机的usb接口)进行通讯,从而达到PC机控制手机的目的。
我们来看看adb的功能,比较常用的功能如下:
第一:交互式shell。可以在PC机上登录到android手机(本质是linux),对android手机进行控制,就像通过ssh远程登录到linux下进行操作一样。其实原理上就是PC上的adb请求android手机上的adbd执行命令,然后把命令的执行结果返回给PC机上的adb,当然中间的通讯数据肯定是通过USB线缆进行传输的。
第二:文件传输。可以将PC上的文件push到手机上,也可以将手机上的文件pull到PC上。当然文件传输数据包同样是走的USB线缆。
第三:安装APK。原理上就是PC机首先把APK文件push到手机上,然后PC发<安装APK>的shell命令给adbd,说穿了还是adb与adbd通讯,通过USB线缆。
第四:调试辅助功能。这个功能是最让新手迷糊的一个功能,也是相对比较难理解的部分,所以要重点说说。adb是android debug bridge的缩写,证明这个程序本身就是以调试为重点的,既然是bridge,那就应当充当一个桥接的作用,事实上adb确实是起到了桥接的作用,接下来我们就来讨论一下。我们知道android上主要由两大类程序构成,JAVA程序和原生C/C++程序。下面分别讨论:
1. JAVA程序调试,了解JAVA调试体系的人都知道 JPDA(Java Platform Debugger Architecture),它是 Java 平台调试体系结构的缩写,通过 JPDA 提供的 API,开发人员可以方便灵活的搭建 Java 调试应用程序。 JPDA 主要由三个部分组成:Java 虚拟机工具接口(JVMTI),Java 调试线协议(JDWP),以及 Java 调试接口(JDI)。
其中JDI由调试前端(front-end)实现,比如jdb工具,比如eclipseIDE,它的两个插件org.eclipse.jdt.debug.ui和org.eclipse.jdt.debug与其强大的调试功能密切相关,其中前者是eclipse调试工具界面的实现,而后者则是JDI的一个完整实现。JVMTI由后端(back-end)实现,比如android中的Davlik虚拟机就实现了JVMTI。 说穿了调试过程就是运行在PC上的前端(如jdb工具,eclipseIDE等) 与 运行在android手机上的后端(Davlik虚拟机)之间通过网络进行通信,通信用的协议就是JDWP。交互如下:
jdb,eclipseIDE等 <==网络通信,用的JDWP协议==> Davlik虚拟机 <==调试==> JAVA程序
[PC机中] [android手机中]
从运行角度讲就是PC机中的jdb,eclipseIDE等进程与android手机中执行JAVA程序的Davlik虚拟机进程之间通过网络socket进行通信,其中Davlik虚拟机进程会bind并且listen某个端口作为调试通信用,而jdb,eclipseIDE等进程会去connect这个端口。
2. 原生C/C++程序,像有些APK中的so文件,android中的各种deamon进程都是属于这种,调试原生C/C++程序需要用到GDB,同样分为前端和后端,比如NDK中包含的
\toolchains\arm-linux-androideabi-4.6\prebuilt\windows\bin\arm-linux-androideabi-gdb.exe 就是一个前端 运行在PC机上,
而\prebuilt\android-arm\gdbserver\gdbserver就是一个后端,运行在android手机上,它是真正的调试器,用于调试原生C/C++程序。
运行在PC机上的arm-linux-androideabi-gdb.exe 与 运行在android手机上gdbserver 之间通过网络socket进行通信,其中gdbserver进程会bind并且listen某个端口
作为调试通信用,而arm-linux-androideabi-gdb.exe进程会去connect这个端口。交互如下:
arm-linux-androideabi-gdb.exe <==网络通信==> gdbserver <==调试==> 原生C/C++程序
[PC机中] [android手机中] [android手机中]
根据上面对JAVA程序调试和原生C/C++程序调试的分析我们可以得知,不管是哪种程序的调试,说的直白些,本质上就是 运行在PC中的A进程 与 运行在android手机中的B进程 之间的网络socket通信的过程。 既然本质是网络socket通讯,那问题就来了,前面已经说过PC和手机之间是通过USB线缆连接的,那怎么样才能进行网络socket通讯呢?ADB使用了一个巧妙的方法用USB模拟了网络通讯。
比如命令:
adb forward tcp:6100 tcp:7100 // PC上所有6100端口通信数据将被重定向到手机端7100端口server上
adb forward tcp:6100 tcp:7100 // PC上所有6100端口通信数据将被重定向到手机端7100端口server上
这个时候adb server会bind和listen 6100这个端口,PC上的其它应用程序,比如A程序,可以connect localhost:6100 ,adb server就会将这个连接请求通过USB线缆传给手机端
的adbd,adbd就会去connect localhost:7100,手机端的listen 7100端口的 B程序就会接到连接请求。交互如下:
A程序 ==连接本机6100==> adb server ==USB线缆==> adbd ==连接本机7100==> B程序
[--------------PC机中---------------] [----------android手机中----------]
看上去就好像 A程序 直接与 B程序 通讯一样。
这样adb就完成了bridge的功能,通过USB线缆将原本不能进行socket连接的PC与手机,巧妙的桥接到了一起。
这种方法还有个特点:就是多条连接可以复用一条链路
比如android手机中 有三个程序 B1,B2,B3 分别listen 8001 8002 8003
那么我们可以
adb forward tcp:7001 tcp:8001
adb forward tcp:7002 tcp:8002
adb forward tcp:7003 tcp:8003
然后 PC机器中 假设有三个程序A1,A2,A3:
程序A1=>connect localhost:7001=>adb server=USB=>adbd=>connect localhost:8001=>B1
程序A2=>connect localhost:7002=>adb server=USB=>adbd=>connect localhost:8002=>B2
程序A3=>connect localhost:7003=>adb server=USB=>adbd=>connect localhost:8003=>B3
虽然实际有三条链路,但是却是共享了一条USB链路进行通信。
文章看到这里,估计就有很多小伙伴会在想,既然一切都是为了网络socket通信,那么如果PC机和手机已经连接到了同一个局域网内,双方之间完全可以直接进行网络socket通信了,是不是就不用那么麻烦了,是不是adb都可以不要了。从某种意义上来说,在这样的情况下 确实可以不用adb了,交互式shell可以直接在手机上装一个ssh server,然后PC上直接ssh,windows下还可以用SecureCRT等工具,文件传输可以直接SCP,调试直接可以用jdb,gdb和手机进行连接调试。事实上互联网上这方面的资料也有很多。但是你如果直接用eclipseIDE的话那还是需要adb,因为eclipseIDE内部会使用adb的功能。既然双方之间已经可以连通,这个时候adb如果再用USB线缆的话感觉有点多此一举,能不能不用USB线缆呢?答案是肯定的。adb支持用wifi连接代替USB连接。首先打开手机的wifi设置,使其连接到网络。然后,需要在手机上对adb连接端口进行设
置,这里需要有root权限的终端(terminal)应用,这种类型的应用在各个Market都有不少,选择一个适合的就可以了。然后,在手机中打开这个终端(terminal)应用,比如输入如下命令:
su
setprop service.adb.tcp.port 5555
stop adbd
start adbd
接着,可以查看一下你的手机的IP地址,最后,在你的PC上,进入到<Android-SDK>/platforms目录,运行如下命令:
adb connect 手机的IP地址:5555 (例如:adb connect 192.168.1.115:5555)如果前面的配置正确无误,则可以得到:connected to 192.168.1.115:5555的输出。
这样,就可以使用adb来对手机进行调试了,此时也可以在Eclipse的设备列表中看到已经连接的手机设备了。
从进程的角度来说 这个就是 运行在PC端的adb.exe进程和运行在手机端的adbd进程之间通过wifi建立的一条socket链路而已。但是站在adb的角度来说,我们要把这条socket链路看成是一条虚拟的USB线缆。要站在更高的高度来理解,这条socket链路就是一根USB线缆:)。 不管adb和adbd之间是通过何种模式通信,他们之间的行为都是一致的,不论是USB线缆链接,还是wifi socket链接。
最后,我们来看看android模拟器,在没有真实手机的情况下可以用android模拟器来调试程序,那么android模拟器和真实的android手机之间在连接方式上有什么区别呢?
android模拟器是qemu-base的,它运行起来后会绑定二个端口,绑定端口会从TCP:5554端口开始,比如机器上运行了2个模拟器,那么先运行的模拟器将绑定5554,5555二个端口,第二个运行的模拟器将绑定5556,5557二个端口,假如有第三个,第四个模拟器要运行就以此类推。其中奇数类的端口就是用于adb连接的。比如PC机上的ADB会去连接第一个模拟器进程的5555的端口,从而建立连接。同理,站在adb的角度来说,我们要把这条socket链路看成是一条虚拟的USB线缆。要站在更高的高度来理解,这条socket链路就是一根USB线缆:)。
这里顺带讲讲偶数类的端口,比如模拟器绑定的5554端口,这个端口是用于控制台的,ddms会通过这个端口连接上模拟器,这样程序员可以通过ddms动态的设置模拟器中的电话状态,比如模拟一个电话呼入,可以设置GPS的数值,从而模拟手机在移动等等。