在编程的过程中经常会碰到一些特殊字符需要进行字符转义才能使程序正常运行,那为什么要进行字符转义才能使程序正常运行呢,我们举几个例子:
例子一:
比如在C语言中 我们想定义一个字符串如 hello,"moses" 那么如果写成
char *str = "hello,"moses",are you ok";
那么程序铁定出错,编译不过,因为双引号"在C语言中是作为定义字符串开始和结束的一个特殊符号来用的,C编译器遇到上面这样的代码直接晕倒,那么必须像下面这样写:
char *str = " hello,\"moses\",are you ok";
加上转义符号\才能让C编译器正确进行认知,简单来说就是,对于C编译器来讲,在字符串中【\"】才等于一个双引号【“】。
例子二:
比如在JS语言中我们定义一个JSON 如
{"content" : "hello,"moses",are you ok"}
同样JS解析引擎也会出错,因为双引号"在JS中也是作为定义字符串开始和结束的一个特殊符号来用的,那么必须像下面这样写:
{"content" : "hello,\"moses\",are you ok"}
加上转义符号\才能让JS解析引擎正确进行认知,简单来说就是,对于JS解析引擎来讲,在字符串中【\"】才等于一个双引号【“】。
例子三:
比如在SQL中,这里假设是MYSQL,我们定义一个SQL语句:
select * from mytable where content like 'hello,'moses',are you ok';
SQL解析引擎会出错,因为单引号'在SQL中是做为字符串开始和结束的一个特殊符号来用的,必须像下面这样写:
select * from mytable where content like 'hello,\'moses\',are you ok';
加上转义符号\才能让SQL解析引擎正确进行认知,简单来说就是,对于SQL解析引擎来讲,在字符串中【\'】才等于一个单引号【’】。
例子四:
比如在HTML中,我们定义如下一个标签:
<input type="text" value="hello,"moses",are you ok">
大家可以在浏览器中试一试,输出会被截断,并不能完整的输出 hello,"moses" 这样的字符串,因为双引号在这里是用来定义标签属性的,所以必须像下面这样写:
<input type="text" value="hello,"moses",are you ok">
这里需要注意的是HTML里面的转义符号是&,而不是符号\。在这个例子上为了在标签属性中表示一个双引号【"】必须要用【"】,当然也可以用【"】来表示,前面那种叫实体名称,后面这种叫实体编号,具体请自行google或者baidu。这里需要强调的是在HTML中是否转义需要根据上下文来,比如:
<html>
<body>
<input type="text" value="hello,"moses",are you ok">
hello,"moses",are you ok
</body>
</html>
这段代码在浏览器中是能正确显示的,因为第二处字符串并没有和任何特殊字符有冲突。当然如果你一定要转义表示那也没任何问题。如下:
<html>
<body>
<input type="text" value="hello,"moses",are you ok">
hello,"moses",are you ok
</body>
</html>
你会发现它在浏览器中也能正确显示,并且显示和前面的一模一样。
这里举了四个例子,总结起来,其实都是一次人机交互的过程,这里的“机器”分别指的是【C编译器】【JS解析引擎】【SQL解析引擎】【HTML解析引擎】,当我们“人”想告诉“机器”,比如告诉【JS解析引擎】我要输入的是一个双引号时,因为双引号对【JS解析引擎】有特殊含义,所以我们必须输入【\"】这样的字符序列给到【JS解析引擎】,这样【JS解析引擎】才会明白我们“人”其实只是想输入一个双引号【"】。
人=>输入序列\"=>JS解析引擎=>理解成=>双引号"
这里需要重点强调的就是关于转义字符问题对于不同的开发语言有着不同的规则,虽然也有很多相同的地方,但是不能预先做假设,需要查阅相关文档。
另外在实际开发过程中经常是各种语言混合开发的,比如做一个网站最常见的形式是 服务端用PHP+MySQL开发,客户端是HTML+JS。服务端PHP代码里面可能会包含SQL语句,而客户端的HTML代码里面可能也会混编入JS代码。那么这个时候我们就必须要有非常清晰的认知,对于一段包含有特殊字符的字符序列来说什么时候由【PHP解析引擎】处理,什么时候由【SQL解析引擎】处理,什么时候由【HTML解析引擎】处理,什么时候由【JS解析引擎】处理,必须搞的明明白白,否则就可能会发生莫名其妙的错误。我们来看一次简单的网页输出过程,很可能是:
【PHP解析引擎】=>sql语句序列=>【SQL解析引擎】=>返回各种结果字符序列=>【PHP解析引擎】=>网络输出给浏览器=>【HTML解析引擎】=>js代码字符序列=>【JS解析引擎】=>执行结果字符序列=>【HTML解析引擎】=>电脑屏幕
简单来说可以理解成一种引擎的输出很可能是作为另一种引擎的输入。其实这也符合计算机系统的基本概念,计算机系统本质上就是输入+处理+输出。
这里我们举几个例子:
我们先来看看例子一,这是一段HTML+JS混编代码,代码如下:
<html>
<body>
<input type="button" value="button" onclick="alert("hello,"moses",are you ok");">
</body>
</html>
这段代码包含了HTML代码也包含了JS代码,这段代码的功能是当点击按钮会弹出一个对话框,对话框的内容是:hello,"moses",are you ok
但是当点击按钮的时候,铁定出错,肯定不会弹出对话框,这么多双引号,估计都晕了,哈哈。既然点击按钮执行的是JS代码,那么首先肯定是想当然的利用JS语言的转义规则进行处理,代码如下:
<html>
<body>
<input type="button" value="button" onclick="alert(\"hello,\"moses\",are you ok\");">
</body>
</html>
结果还是不行,而且错得一塌糊涂,看样子想当然是不行的了,还的仔细捋一捋把来龙去脉搞清楚才能解决。首先我们必须得先明白,上面的代码是首先被【HTML解析引擎】解析后才会交给【JS解析引擎】处理,那么看看上面的代码被【HTML解析引擎】解析后是个什么样子,因为符号\并不是【HTML解析引擎】的转义符,所以最后交给JS执行的代码是alert(\,不出错才怪。既然是先被【HTML解析引擎】解析,那么我们肯定得先用HTML的转义规则来处理,修改后的代码如下:
<html>
<body>
<input type="button" value="button" onclick="alert("hello,"moses",are you ok");">
</body>
</html>
可惜的是这样修改后还是不能正常工作,那是为什么呢,仔细分析一下就可以得知,这段代码被【HTML解析引擎】解析出来的JS代码实际如下:
alert(“hello,”moses“,are you ok”);
这行代码交给【JS解析引擎】后肯定会出错,原因就是中间那两个双引号,必须要按JS语言的规则转义,应该修改成下面这样子:
alert(“hello,\”moses\“,are you ok”);
这样才能正常工作,那么现在我们把HTML和JS两种规则结合起来处理后,得到了最终如下的整合代码:
<html>
<body>
<input type="button" value="button" onclick="alert("hello,\"moses\",are you ok");">
</body>
</html>
至此,程序终于能按照期望运行了。当然实际上我们可以通过双引号和单引号配合使用来解决问题,但是这里我们为了很好的说明问题的来龙去脉,所以不会考虑其他途径。
接下来看看例子二,这是一段PHP+SQL混编代码,为了更好的说明原理和问题,这里全部使用单引号,代码如下:
<?php
$con = mysql_connect('localhost','root','123456');
mysql_select_db('db_test', $con);
mysql_query('INSERT INTO T_Test (F_Content) VALUES ('hello,'moses',are you ok')');
mysql_close($con);
?>
代码的目的是将字符序列 hello,'moses',are you ok 插入数据库中,但是上面这代码肯定是错的,因为对于【PHP解析引擎】来说单引号是作为定义字符串开始和结束的一个特殊字符,所以这里肯定必须进行转义处理,而PHP也是用符号\来作为转义符的,所以我们将代码改成如下样子:
<?php
$con = mysql_connect('localhost','root','123456');
mysql_select_db('db_test', $con);
mysql_query('INSERT INTO T_Test (F_Content) VALUES (\'hello,\'moses\',are you ok\')');
mysql_close($con);
?>
不幸的是,这段代码还是无法正常工作,那是为什么呢,我们来分析一下原因。首先要说的是这段代码是先交给【PHP解析引擎】解析后再把其中的SQL语句交给MySQL的【SQL解析引擎】来处理,有了这个前提后就比较好分析了,我们先来看看通过【PHP解析引擎】解析后出来的代码是什么样子:
解析之前:
INSERT INTO T_Test (F_Content) VALUES (\'hello,\'moses\',are you ok\')
解析之后:
INSERT INTO T_Test (F_Content) VALUES ('hello,'moses',are you ok')
然后解析之后的SQL语句会交给【SQL解析引擎】来处理,答案很明显了,肯定出错,因为在【SQL解析引擎】中单引号也是定义字符串开始和结束的特殊符号。那么这里要重点强调的是:
【PHP解析引擎】解析是没问题的,但是在【SQL解析引擎】解析的时候出错了。
然后接下来我们继续修改代码:
<?php
$con = mysql_connect('localhost','root','123456');
mysql_select_db('db_test', $con);
mysql_query('INSERT INTO T_Test (F_Content) VALUES (\'hello,\\'moses\\',are you ok\')');
mysql_close($con);
?>
一运行,代码还是出错,这又是为什么呢,那是因为中间\\'这样的语法出现了问题,前面那个\将后面的\给转义了从而失去了转义的特性导致单引号没被转义,所以直接在【PHP解析引擎】解析的时候就出错了,那么这里要重点强调的是:
这次是【PHP解析引擎】解析的时候就已经出问题了,压根和【SQL解析引擎】没啥关系。
只能继续修改代码了,修改后的代码如下:
<?php
$con = mysql_connect('localhost','root','123456');
mysql_select_db('db_test', $con);
mysql_query('INSERT INTO T_Test (F_Content) VALUES (\'hello,\\\'moses\\\',are you ok\')');
mysql_close($con);
?>
这次终于成功了,顺利执行完毕,数据也正常写入成功。我们来分析一下这次为什么可以:
【PHP解析引擎】解析前的代码:
INSERT INTO T_Test (F_Content) VALUES (\'hello,\\\'moses\\\',are you ok\')
【PHP解析引擎】解析后的代码:
INSERT INTO T_Test (F_Content) VALUES ('hello,\'moses\',are you ok')
然后再把这句SQL交给【SQL解析引擎】解析,根据转义规则,【SQL解析引擎】也非常清楚的明白要写入的数据里面包含有2个单引号,而不会发生冲突,最终数据终于成功的写入了。
如图:
最后要说的是在实际开发中其实有很多办法可以解决类似的问题,比如单引号和双引号配合使用,比如magic_quotes_gpc=on,addslashes和stripslashes,mysql_real_escape_string等等函数都能比较好的解决问题。
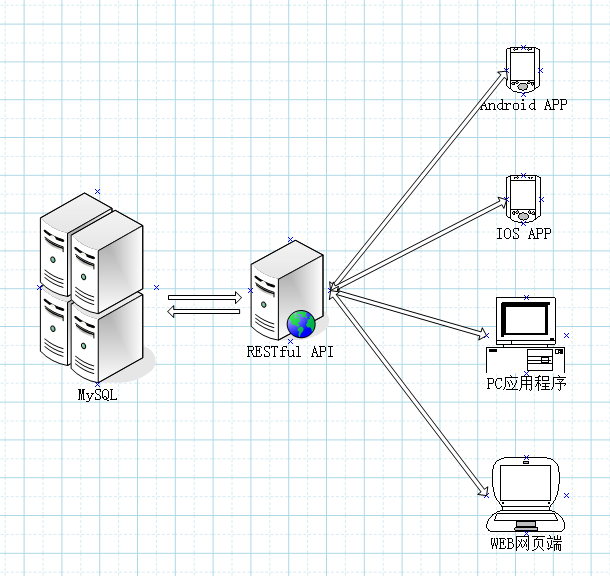
好了,具体的技术细节就说到这里了,那么接下来我们从宏观架构的角度来简单讨论一下这个话题。在项目的实际开发中要考虑的转义字符不单单只有引号,还有诸如<,>,&等等很多很多,这里只讨论几个最常见的。这些转义字符如果不做处理,可能会导致很大的安全隐患,比如古老的SQL注入技术,比如XSS攻击,这里举个最简单的例子,比如在一个文章发布系统里面不做任何特殊处理,那么有人在提交的文章里面加入一个<script src='x.js'>这样的标签那就麻烦大了,所以要做处理。那么到底什么时候做处理呢,我们先看一幅图:
这是现在最为常见的系统架构,一个软件可能会有不同平台的客户端,大家都统一通过RESTfulAPI进行通讯,一个典型的例子就是微信,它有PC端,Android端,IOS端,WEB端等等。
我们在设计这样的系统的时候 RESTfulAPI可能会用PHP,Java,NodeJS等语言开发,Android端开发有Java,IOS上有Objective-C,PC上用C/C++,.Net,Delphi等等,WEB端有HTML+JS。
你会发现这么多语言各有各的规则,所以最好的办法就是在保证安全的前提下输入的数据不做转换直接进入到数据库,输出的数据也不做转换直接给到客户端,然后各种客户端都根据自己的实际情况自行处理,这里打个简单的比方:
比如用户输入一段字符序列 【hello<hr>"<br>】,那么最终进入数据库的也要是同样的序列,而不应该是【hello<hr>"<br>】,因为这样的转换HTML认得,但是其他客户端比如C/C++就不认得,就会造成各种困扰,所以最终的处理过程应该留给各个客户端自行处理。