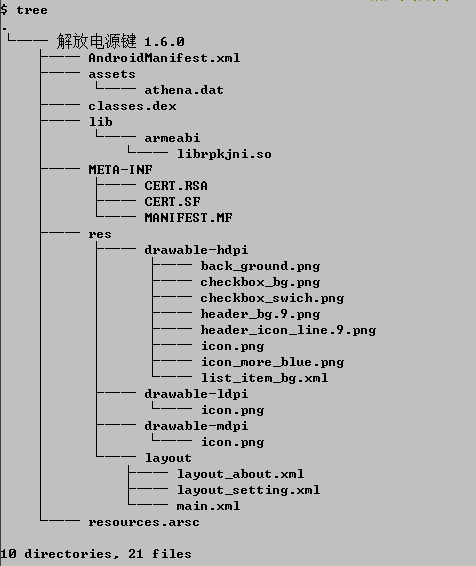
android手机在双击点亮屏幕功能出来以前,为了点亮屏幕得频繁的使用电源键,时间长了电源键容易损坏,所以聪明的人们就开发出用音量键来点亮屏幕的apk程序,安装这样的apk后,点击音量+键或者音量-键都可以点亮屏幕,这样就大大提高了电源键的使用寿命。最近突然对这类功能有点好奇,所以利用空闲时间研究了其中一个apk,叫做【解放电源键 1.6.0】,看了软件的关于信息,作者叫王龙,向他致敬。另外此程序需要root权限支持。首先来看看包结构,如图:
其中比较可疑的是assets/athena.dat文件,经证实这是一个可执行文件,只是取了一个.dat的后缀名迷惑人而已,利用ps查看进程可以得知,如图:
另外利用cat查看内存布局也确定lib/armeabi/librpkjni.so文件也已经被加载,如图:
那么到此分析的重点就在classes.dex,librpkjni.so,athena.dat三个文件上面。
对于dex文件有三个比较好的工具进行反汇编。
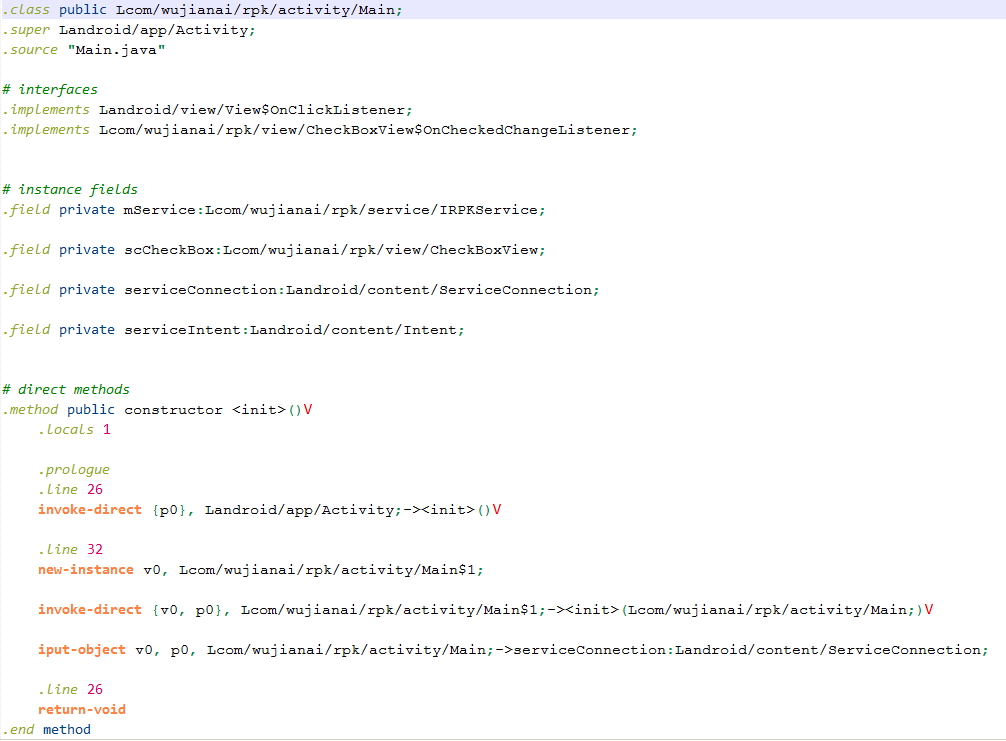
一个是 baksmali 或者直接用apktool(内部集成了baksmali ),它会将dex反汇编成smali文件。其实就是文本文件可以直接查看,我用设置了语法高亮的Notepad++查看。效果如图:
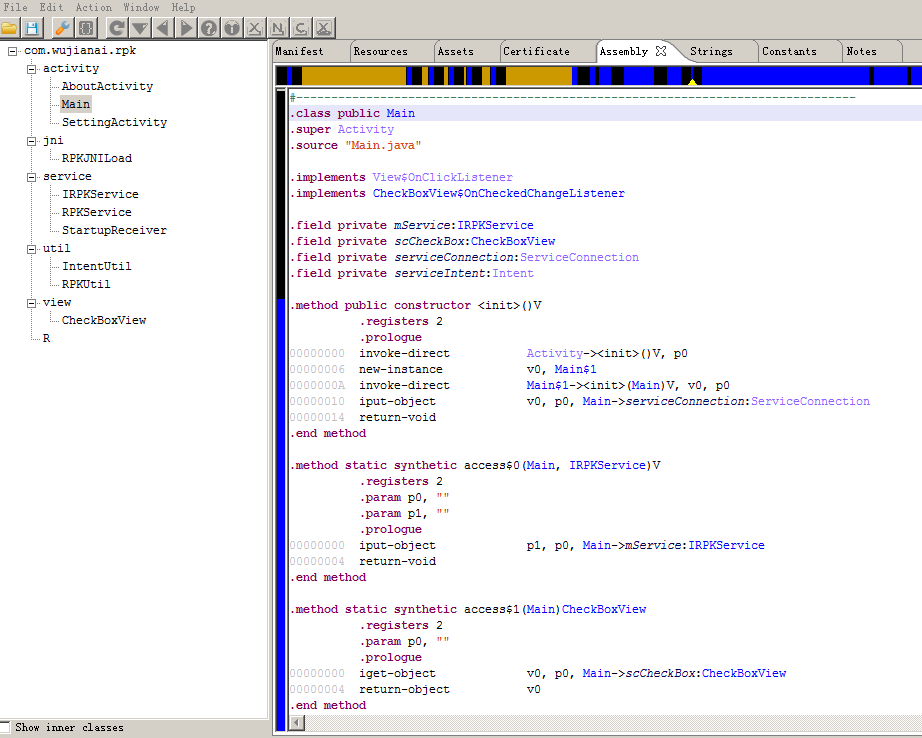
二个是用JEB,这是个收费软件 官方网站以前是http://www.android-decompiler.com/ 后来改成了https://www.pnfsoftware.com/ 效果如图:
三是用IDA,IDA Pro从6.1版本开始支持Android。包括Dalvik指令集的反汇编、原生库(ARM/Thumb代码)的反汇编、原生库(ARM/Thumb代码)的动态调试等,IDA 6.6新添加了对dex文件的动态调试支持,具体可以查阅相关文档。效果如图:
这三种工具对Dalvik指令的语法解析上都有些许不同,至于选择何种工具,可以根据自己的喜好来。 而对于librpkjni.so和athena.dat这2个原生程序的反汇编那毫无疑问肯定是用IDA了。
接下来正式进入流程,这里我们只关心关键点,至于其他的就不做过多说明了。通过分析AndroidManifest.xml文件可以得知入口activity是 com.wujianai.rpk.activity.Main,另外有一个服务
是 com.wujianai.rpk.service.RPKService。先看 com.wujianai.rpk.activity.Main的onCreate函数:
.method public onCreate(Bundle )V
.registers 8
.param p1, "savedInstanceState"
.prologue
//////////////////////////////////////////////////// 代码省略。。。。。。
////////////////////////////////////////////////////
000000A0 iget-object v3, p0, Main->serviceIntent :Intent
000000A4 iget-object v4, p0, Main->serviceConnection :ServiceConnection
000000A8 const/4 v5, 0x1
000000AA invoke-virtual Main->bindService (Intent, ServiceConnection, I)Z, p0, v3, v4, v5
000000B0 invoke-direct Main->hasRoot ()Z, p0
000000B6 move-result v3
000000B8 if-nez v3, :C2
:BC
000000BC invoke-direct Main->doNoRoot ()V, p0
:C2
000000C2 return-void
.end method
这里会启动RPKService服务,同时会调用hasRoot函数检查是否有root权限。
来看看hasRoot函数是如何检查是否有root权限的:
.method private hasRoot()Z
.registers 8
00000000 const/4 v6, 0x0
.prologue
00000002 const/16 v4, 0x400
00000006 new-array v0, v4, [C
:A
.local v0, buf:[C
0000000A invoke-static Runtime->getRuntime ()Runtime
00000010 move-result-object v4
00000012 const-string v5, "su -c ls"
00000016 invoke-virtual Runtime->exec(String )Process, v4, v5
0000001C move-result-object v2
.local v2, exec:Ljava/lang/Process;
0000001E new-instance v3, InputStreamReader
00000022 invoke-virtual Process->getErrorStream ()InputStream, v2
00000028 move-result-object v4
0000002A invoke-direct InputStreamReader-><init> (InputStream)V, v3, v4
.local v3, r:Ljava/io/InputStreamReader;
00000030 invoke-virtual InputStreamReader->read([C)I, v3, v0
:36
00000036 move-result v4
00000038 const/4 v5, 0xFFFFFFFFFFFFFFFF
0000003A if-ne v4, v5, :42
:3E
0000003E const/4 v4, 0x1
:40
00000040 return v4
:42
00000042 move v4, v6
00000044 goto :40
:46
00000046 move-exception v4
00000048 move-object v1, v4
.local v1, e:Ljava/io/IOException;
0000004A move v4, v6
0000004C goto :40
.catch IOException {:A .. :36} :46
.end method
原来是看"su -c ls"命令能否执行成功来判断的:)
接下来看看RPKService服务启动后会干些什么:
.method public run()V
.registers 6
.prologue
00000000 new-instance v1, StringBuilder
00000004 invoke-direct StringBuilder-><init> ()V, v1
:A
.local v1, res:Ljava/lang/StringBuilder;
0000000A invoke-static Runtime->getRuntime ()Runtime
00000010 move-result-object v2
00000012 new-instance v3, StringBuilder
00000016 const-string v4, "su -c ./"
0000001A invoke-direct StringBuilder-><init> (String)V, v3, v4
00000020 iget-object v4, p0, RPKService$3->val$file :File
00000024 invoke-virtual File->getAbsolutePath ()String, v4
0000002A move-result-object v4
0000002C invoke-virtual StringBuilder->append (String) StringBuilder, v3, v4
00000032 move-result-object v3
00000034 invoke-virtual StringBuilder->toString ()String, v3
0000003A move-result-object v3
0000003C invoke-virtual Runtime->exec(String )Process, v2, v3
:42
00000042 return-void
:44
00000044 move-exception v2
00000046 move-object v0, v2
.local v0, ex:Ljava/lang/Exception;
00000048 const-string v2, "wanghelong"
0000004C invoke-virtual StringBuilder->toString ()String, v1
00000052 move-result-object v3
00000054 invoke-static Log->e(String , String)I, v2, v3
0000005A goto :42
.catch Exception {:A .. :42} :44
.end method
.method public runScipt()V
.registers 5
.prologue
00000000 new-instance v0, File
00000004 const-string v2, "bin"
00000008 const/4 v3, 0x0
0000000A invoke-virtual RPKService->getDir (String, I) File, p0, v2, v3
00000010 move-result-object v2
00000012 const-string v3, "athena.dat"
00000016 invoke-direct File-><init> (File, String)V, v0, v2, v3
.local v0, file:Ljava/io/File;
0000001C new-instance v1, RPKService$3
00000020 invoke-direct RPKService$3-><init> (RPKService, File)V, v1, p0, v0
.local v1, thread:Ljava/lang/Thread;
00000026 invoke-virtual Thread->start()V, v1
0000002C return-void
.end method
.method private static copyRawFile (Context, InputStream, File , String)V
.registers 10
.annotation system Throws
value = {
IOException,
InterruptedException
}
.end annotation
.param p0, "ctx"
.param p1, "inputStream"
.param p2, "file"
.param p3, "mode"
.prologue
00000000 new-instance v2, FileOutputStream
00000004 invoke-direct FileOutputStream-><init> (File)V, v2, p2
.local v2, out:Ljava/io/FileOutputStream;
0000000A const/16 v3, 0x400
0000000E new-array v0, v3, [B
:12
.local v0, buf:[B
00000012 invoke-virtual InputStream->read([B)I, p1, v0
00000018 move-result v1
.local v1, len:I
0000001A if-gtz v1, :7C
:1E
0000001E invoke-virtual FileOutputStream->close()V, v2
00000024 invoke-virtual InputStream->close()V, p1
0000002A invoke-static Runtime->getRuntime ()Runtime
00000030 move-result-object v3
00000032 new-instance v4, StringBuilder
00000036 const-string v5, "chmod "
0000003A invoke-direct StringBuilder-><init> (String)V, v4, v5
00000040 invoke-virtual StringBuilder->append (String) StringBuilder, v4, p3
00000046 move-result-object v4
00000048 const-string v5, " "
0000004C invoke-virtual StringBuilder->append (String) StringBuilder, v4, v5
00000052 move-result-object v4
00000054 invoke-virtual File->getAbsolutePath ()String, p2
0000005A move-result-object v5
0000005C invoke-virtual StringBuilder->append (String) StringBuilder, v4, v5
00000062 move-result-object v4
00000064 invoke-virtual StringBuilder->toString ()String, v4
0000006A move-result-object v4
0000006C invoke-virtual Runtime->exec(String )Process, v3, v4
00000072 move-result-object v3
00000074 invoke-virtual Process->waitFor ()I, v3
0000007A return-void
:7C
0000007C const/4 v3, 0x0
0000007E invoke-virtual FileOutputStream->write([B, I, I)V, v2, v0, v3, v1
00000084 goto :12
.end method
.method private initAssets ()V
.registers 7
00000000 const-string v5, "athena.dat"
.prologue
00000004 invoke-virtual RPKService->getAssets ()AssetManager, p0
0000000A move-result-object v0
.local v0, assetManager:Landroid/content/res/AssetManager;
0000000C new-instance v2, File
00000010 const-string v3, "bin"
00000014 const/4 v4, 0x0
00000016 invoke-virtual RPKService->getDir (String, I) File, p0, v3, v4
0000001C move-result-object v3
0000001E const-string v4, "athena.dat"
00000022 invoke-direct File-><init> (File, String)V, v2, v3, v5
.local v2, file:Ljava/io/File;
00000028 invoke-virtual File->exists ()Z, v2
0000002E move-result v3
00000030 if-nez v3, :4A
:34
00000034 const-string v3, "athena.dat"
00000038 invoke-virtual AssetManager->open(String )InputStream, v0, v3
0000003E move-result-object v3
00000040 const-string v4, "777"
00000044 invoke-static RPKService->copyRawFile (Context, InputStream, File, String )V, p0, v3, v2, v4
:4A
0000004A return-void
:4C
0000004C move-exception v3
0000004E move-object v1, v3
.local v1, e:Ljava/lang/Exception;
00000050 invoke-virtual Exception->printStackTrace ()V, v1
00000056 goto :4A
.catch Exception {:34 .. :4A} :4C
.end method
.method private onServiceStart ()V
.registers 1
.prologue
00000000 invoke-direct RPKService->initAssets ()V, p0
00000006 invoke-virtual RPKService->runScipt ()V, p0
0000000C return-void
.end method
总结起来就一句话:释放athena.dat这个可执行文件然后修改成可执行属性后再执行它。
RPKService服务还会启动一个线程:
.method public onStartCommand(Intent , I, I)I
.registers 5
.param p1, "intent"
.param p2, "flags"
.param p3, "startId"
.prologue
00000000 invoke-super Service->onStartCommand (Intent, I, I)I, p0, p1, p2, p3
00000006 iget-object v0, p0, RPKService->thread :Thread
0000000A invoke-virtual Thread->isAlive ()Z, v0
00000010 move-result v0
00000012 if-nez v0, :20
:16
00000016 iget-object v0, p0, RPKService->thread :Thread
0000001A invoke-virtual Thread->start()V, v0
:20
00000020 const/4 v0, 0x3
00000022 return v0
.end method
线程是在RPKService的构造函数里面定义的:
.method public run()V
.registers 5
.prologue
00000000 const/4 v1, 0xFFFFFFFFFFFFFFFE
00000002 invoke-static Process->setThreadPriority (I)V, v1
00000008 const/4 v0, 0x0
:A
.local v0, wakeLock:Landroid/os/PowerManager$WakeLock;
0000000A iget-object v1, p0, RPKService$2->this$0 :RPKService
0000000E invoke-static RPKService->access$3 (RPKService) RPKJNILoad, v1
00000014 move-result-object v1
00000016 invoke-virtual RPKJNILoad->fun1()V, v1
0000001C invoke-static Thread->interrupted ()Z
00000022 move-result v1
00000024 if-eqz v1, :2A
:28
00000028 return-void
:2A
0000002A iget-object v1, p0, RPKService$2->this$0 :RPKService
0000002E invoke-static RPKService->access$4 (RPKService) PowerManager, v1
00000034 move-result-object v1
00000036 const v2, 0x1000000A
0000003C const-string v3, "RPKService"
00000040 invoke-virtual PowerManager->newWakeLock (I, String)PowerManager$WakeLock , v1, v2, v3
00000046 move-result-object v0
00000048 const-wide/16 v1, 0x1388
0000004C invoke-virtual PowerManager$WakeLock->acquire (J)V, v0, v1, v2
00000052 goto :A
.end method
这个线程里面会调用librpkjni.so中的fun1函数,此时线程会阻塞在这个函数当中,一直等待,直到这个函数返回,线程就会调用PowerManager->newWakeLock 点亮屏幕(终于看到核心点了)。这里的PowerManager是电源管理器,在之前由getSystemService(Context.POWER_SERVICE)赋值。那么问题来了,librpkjni.so中的fun1函数内部到底做了什么呢?为了搞清楚这个问题我们接下来要开始分析librpkjni.so和athena.dat这两个原生程序了。
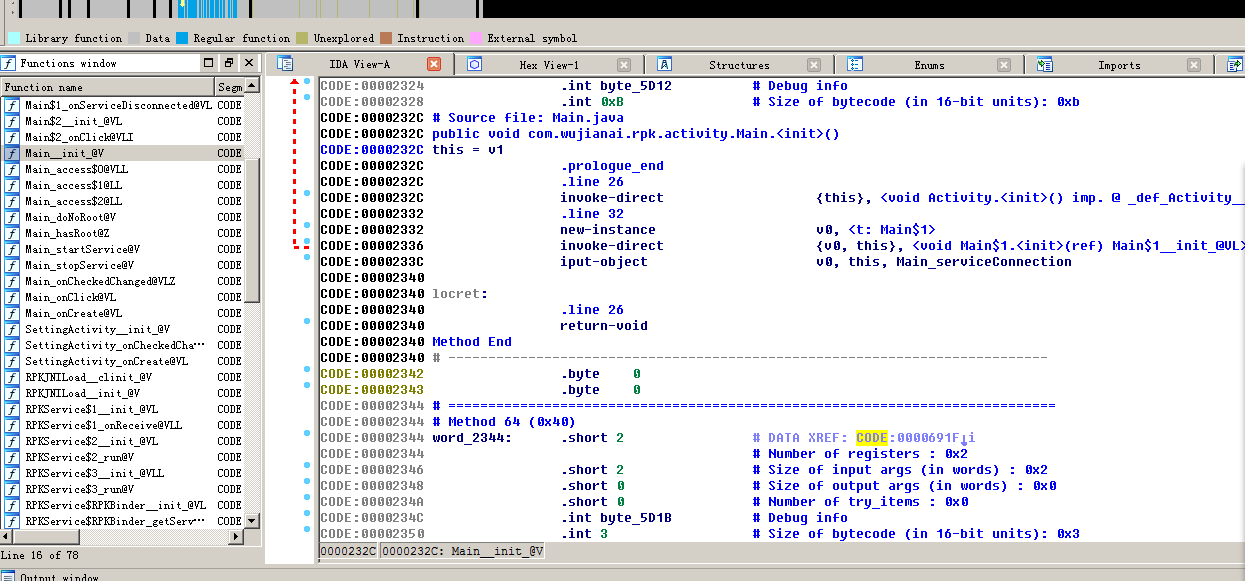
先看看librpkjni.so中的fun1函数(JNI相关的知识可自行查询资料),如图:
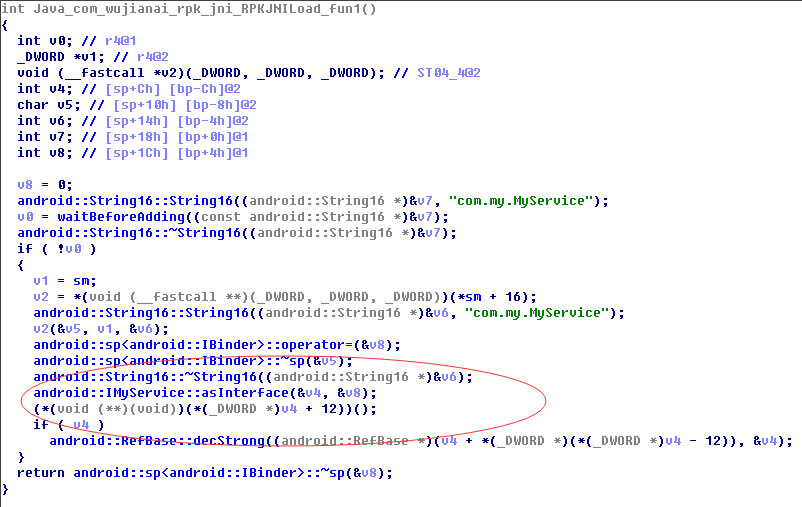
将其还原成伪代码大概就是下面这个样子:
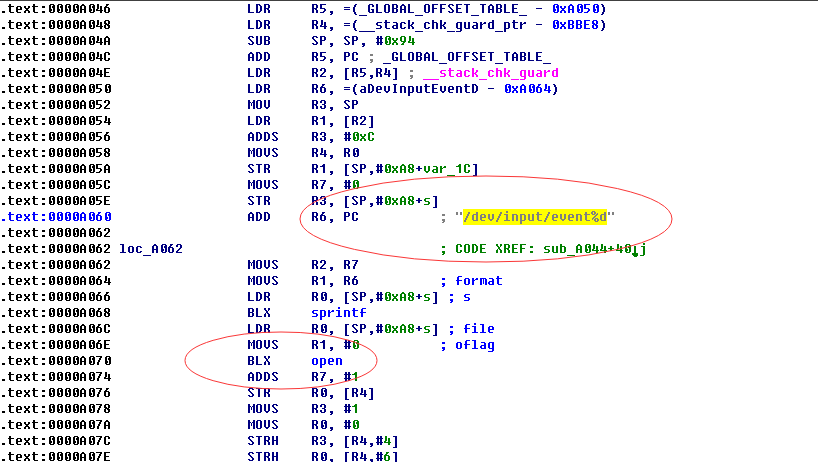
其实本质上就是在做进程间通讯,和一个名叫com.my.MyService的服务通讯,而这个服务就是在athena.dat进程中实现的(android服务是一个复杂的系统,包含java层面的服务,原生层面的服务,服务管理器等等,具体的细节请自行查阅相关资料)。记住athena.dat进程是以root权限运行的,它会监听linux输入子系统,判断用户是否有按音量键,如图:
通过打开/dev/input/event系列设备进行监听,一旦用户按了音量键athena.dat进程就会捕获到,这样librpkjni.so中的fun1函数就会返回,应用中等待的线程就会继续执行调用
PowerManager->newWakeLock 点亮屏幕。完成一次点亮屏幕的过程。
最后总结一下:站在linux进程的角度来讲本程序运行后会产生2个进程,一个APK主进程,一个athena.dat进程(root权限运行),APK主进程中会调用librpkjni.so中的fun1函数与
athena.dat进程通讯并且一直等待通知。而在athena.dat进程中会监听linux输入子系统来判断用户是否按了电源键,如果用户按了电源键后 APK主进程中的librpkjni.so中的fun1函数
就会结束等待,代码就会执行到PowerManager->newWakeLock 从而点亮屏幕。具体详细可参阅源代码。
全部代码已经上传到github上,为了演示和编译的方便,源代码中进程通讯部分没有利用andorid的binder机制,只是简单的用了管道来实现,因为要实现
android服务需在android源代码环境下进行开发和编译,比较麻烦,所以就简单处理之。
补充说明:原版程序在android5.x的系统上是失效的,原因是athena.dat进程运行不起来,手动运行此文件会报错:error: only position independent executables (PIE) are supported.
原因是google给android5.0增加了新的安全特性,不支持PIE(position independent executables)的程序都不能运行。所以编译的时候要加上-pie -fPIE 的选项,这样才能在android5.x系统上正常运行。
源代码的github地址:
https://github.com/phonegapX/com.wujianai.rpk